



| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- EC2
- terraform
- Athena
- Jenkins
- lambda
- FSX
- security group
- VPC
- NaCl
- ncp
- ALB
- S3
- Subnet
- AWS
- dns
- Windows
- RDS
- Storage
- 도메인
- CLI
- Python
- Dedup
- 네이버 클라우드 플랫폼
- 윈도우
- CloudFront
- Linux
- route table
- 테라폼
- AD
- storage gateway
- Today
- Total
끄적이는 보송
[AWS] Athena로 CloudTrail 로그 분석 본문

오늘은 깊게 분석할 것 없이 아래의 간단한 실습을 해볼 생각이다.
1. CloudTrail 생성 및 로그가 S3에 쌓이도록 구성
2. S3에 쌓인 로그 파일을 Athena로 분석하기
굳이 CloudTrail 로그를 S3에 올리는 이유는 CloudTrail의 최대 로그 보존 기간이 90일이기 때문이다. 그 이전의 데이터는 유지하지 않기에 간혹 과거의 데이터를 조회하지 못해 난감한 경우가 있었다. (누가 어떤 작업을 했는지, CreateInstance 로그 등등) 또한 로그 파일이 쌓이다 보면 일일이 수많은 파일을 열어 확인해야 하는 번거로움이 있는데 이를 Athena를 활용해 쿼리를 날려 내가 원하는 데이터를 추릴 수 있다. 오늘은 이 실습을 해보려 한다.
1. CloudTrail 생성 및 로그가 S3에 쌓이도록 구성
방법은 간단하다. CloudTrail 서비스 콘솔 환경에 접근해 Trail을 생성해주면 된다. 생성할 때 아래 정보만 기입해주면 CloudTrail 생성과 동시, 지정한 S3버킷에 로그가 쌓이게 된다.
아래 AWS 공식 도큐먼트를 읽어보면 CloudTrail 로그를 S3 버킷에 쌓기 위해선 아래의 내용을 Bucket Policy에 추가해줘야 한다고 한다. 그런데 위 콘솔 작업을 마치고 막상 S3 Buckeet Policy를 확인해보면 이미 자동으로 수정되어 있었다. CloudFront OAI 설정할 때처럼 AWS에서 센스 있게 알아서 추가해주는 듯하다.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AWSCloudTrailAclCheck20150319",
"Effect": "Allow",
"Principal": {"Service": "cloudtrail.amazonaws.com"},
"Action": "s3:GetBucketAcl",
"Resource": "arn:aws:s3:::myBucketName",
"Condition": {
"StringEquals": {
"aws:SourceArn": "arn:aws:cloudtrail:region:myAccountID:trail/trailName"
}
}
},
{
"Sid": "AWSCloudTrailWrite20150319",
"Effect": "Allow",
"Principal": {"Service": "cloudtrail.amazonaws.com"},
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::myBucketName/[optionalPrefix]/AWSLogs/myAccountID/*",
"Condition": {
"StringEquals": {
"s3:x-amz-acl": "bucket-owner-full-control",
"aws:SourceArn": "arn:aws:cloudtrail:region:myAccountID:trail/trailName"
}
}
}
]
}CloudTrail에 대한 Amazon S3 버킷 정책 - AWS CloudTrail
기존 버킷에 이미 하나 이상의 정책이 연결되어 있는 경우 CloudTrail 액세스용 문을 해당 정책에 추가합니다. 버킷에 액세스하는 사용자에게 적절한지 발생한 권한 집합을 평가합니다.
docs.aws.amazon.com
2. S3에 쌓인 로그 파일을 Athena로 분석하기
운영을 하다 보면 아래처럼 각 Region, 날짜별로 거의 5분 단위로 로그가 쌓인다. 위 실습으로 방금 막 CloudTrail을 생성한 사용자라면 조금만 기다리면 로그 파일이 지정한 S3 버킷 경로에 생성되는 것을 볼 수 있을 것이다. 무튼 이 많은 로그에 특정 데이터를 찾아야 한다면 조금 막막할 수 있다. 하지만 Athena를 사용하면 저 많은 파일의 데이터를 하나의 DB에 모아, 사용자는 DB 데이터 기반으로 로그를 검색할 수가 있다.
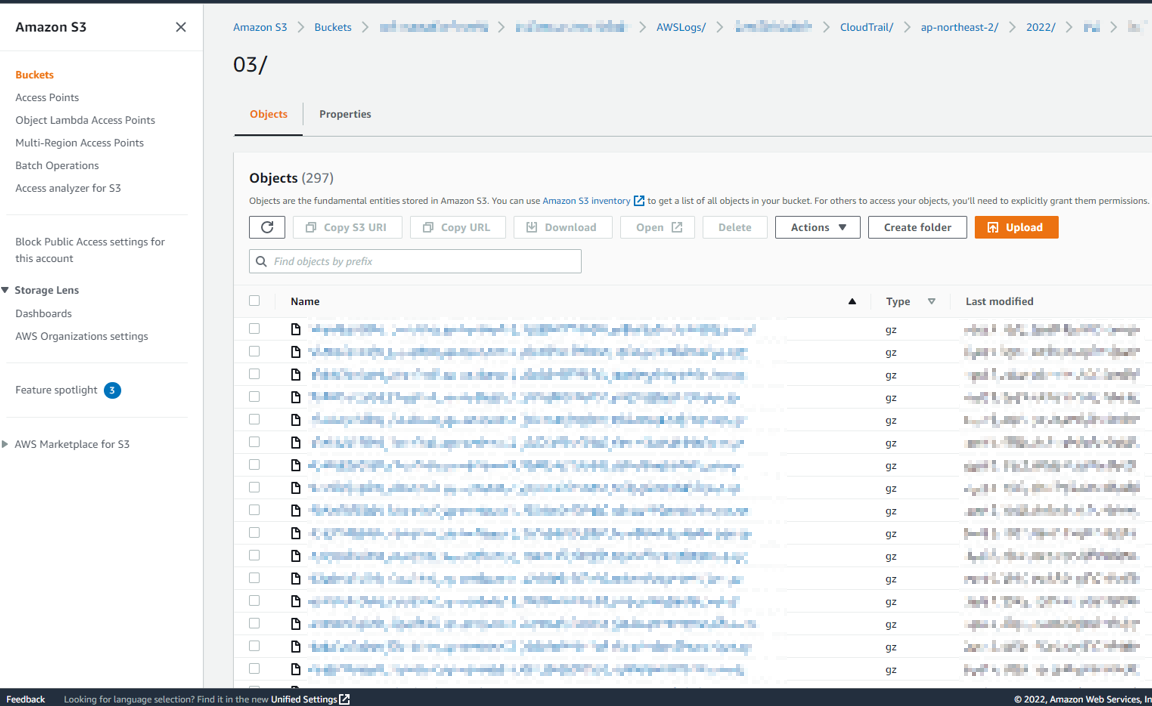
Athena 서비스 화면에 접근하여 쿼리 창에 아래 내용을 입력해주자. 대충 CloudTrail 로그 파일에 맞게 Table을 생성하고, 지정한 S3 버킷 경로에 있는 모든 파일의 데이터를 Table 형식에 맞게 불러오겠다는 내용이다. 나의 경우, AWS 도큐먼트에 안내되어 있는 쿼리문 중 'PARTIONED BY' 부분은 제외하고 입력해줬다. 우리가 수정해줘야 하는 내용은 쿼리 맨 윗줄의 TABLE 이름과 쿼리 맨 아랫줄의 LOCATION의 S3 버킷 경로 부분이다.
CREATE EXTERNAL TABLE cloudtrail_logs (
eventversion STRING,
useridentity STRUCT<
type:STRING,
principalid:STRING,
arn:STRING,
accountid:STRING,
invokedby:STRING,
accesskeyid:STRING,
userName:STRING,
sessioncontext:STRUCT<
attributes:STRUCT<
mfaauthenticated:STRING,
creationdate:STRING>,
sessionissuer:STRUCT<
type:STRING,
principalId:STRING,
arn:STRING,
accountId:STRING,
userName:STRING>>>,
eventtime STRING,
eventsource STRING,
eventname STRING,
awsregion STRING,
sourceipaddress STRING,
useragent STRING,
errorcode STRING,
errormessage STRING,
requestparameters STRING,
responseelements STRING,
additionaleventdata STRING,
requestid STRING,
eventid STRING,
resources ARRAY<STRUCT<
ARN:STRING,
accountId:STRING,
type:STRING>>,
eventtype STRING,
apiversion STRING,
readonly STRING,
recipientaccountid STRING,
serviceeventdetails STRING,
sharedeventid STRING
)
ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde'
STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://CloudTrail_bucket_name/AWSLogs/Account_ID/CloudTrail/';https://docs.aws.amazon.com/ko_kr/athena/latest/ug/cloudtrail-logs.html
AWS CloudTrail 로그 쿼리 - Amazon Athena
추적과 연결된 버킷의 이름을 찾으려면 CloudTrail 탐색 창에서 추적을 선택하고 추적의 S3 버킷 열을 표시합니다. 버킷의 Amazon S3 위치를 보려면 S3 버킷 열에서 버킷에 대한 링크를 선택합니다. 그
docs.aws.amazon.com
이대로 쿼리를 실행하려고 하면 아래처럼 안될 것이다. 이전에 먼저 해줘야 하는 것이 있다.
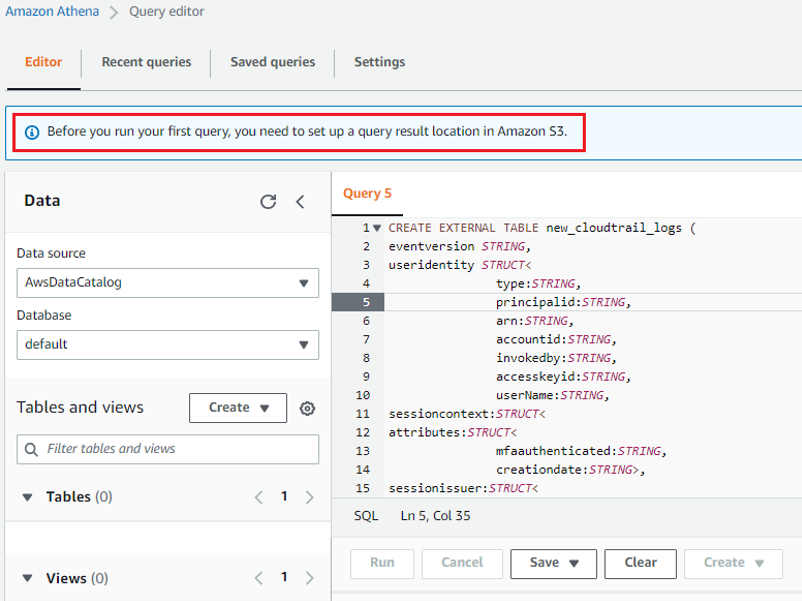
Settings에 접근해 쿼리 결과를 저장할 위치를 지정해줘야 한다.
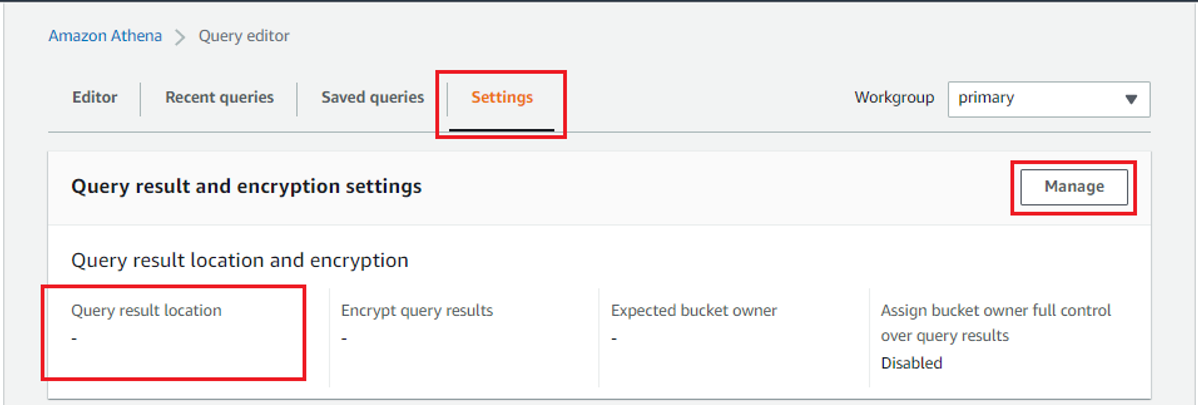
적당히 S3 버킷의 특정 경로에 쿼리 결과를 저장하겠다는 설정을 해줬다.
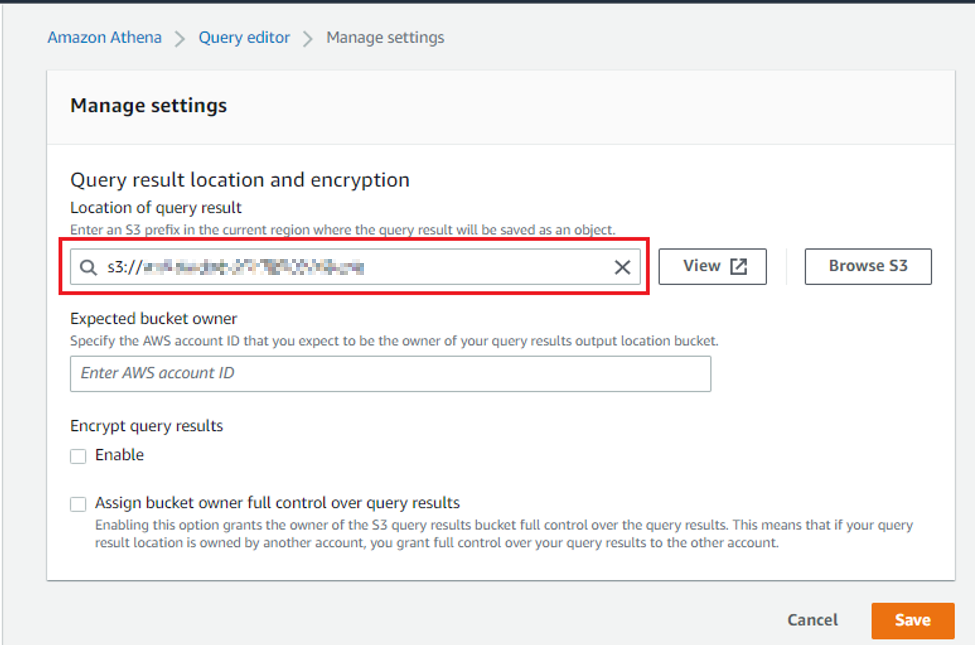
쿼리를 실행시켜보니 Table이 정상적으로 생성되었다.
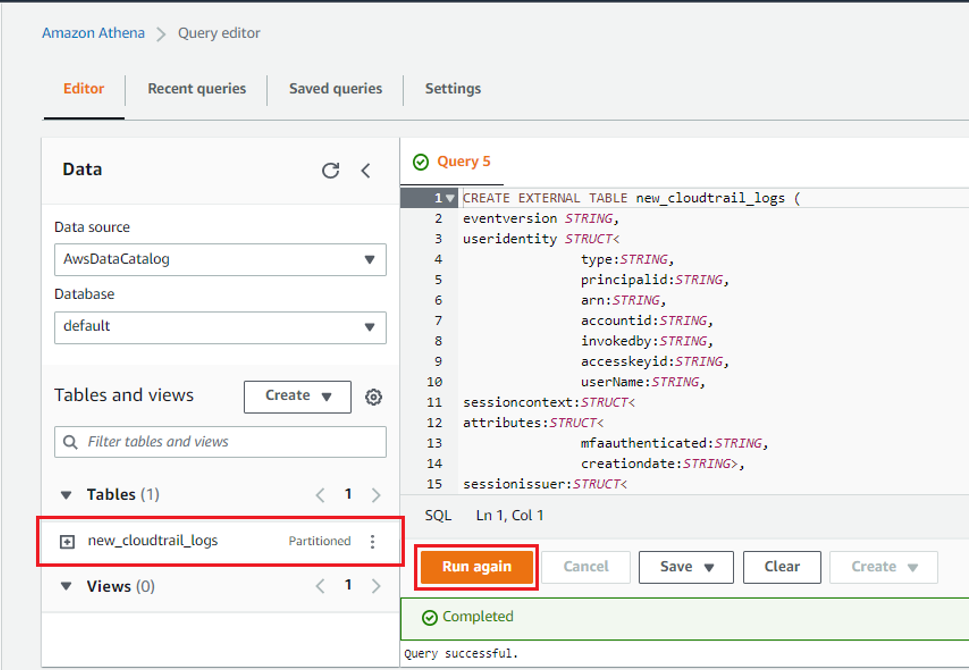
이제 테이블 안에 있는 필요한 데이터만 불러와 확인하면 된다. default 데이터베이스에 new_cloudtrail_logs라는 테이블에서 eventsource가 ec2.amazonaws.com과 일치한 데이터를 모두 불러와 보았다.
"SELECT * FROM "default"."new_cloudtrail_logs" WHERE (eventsource='ec2.amazonaws.com');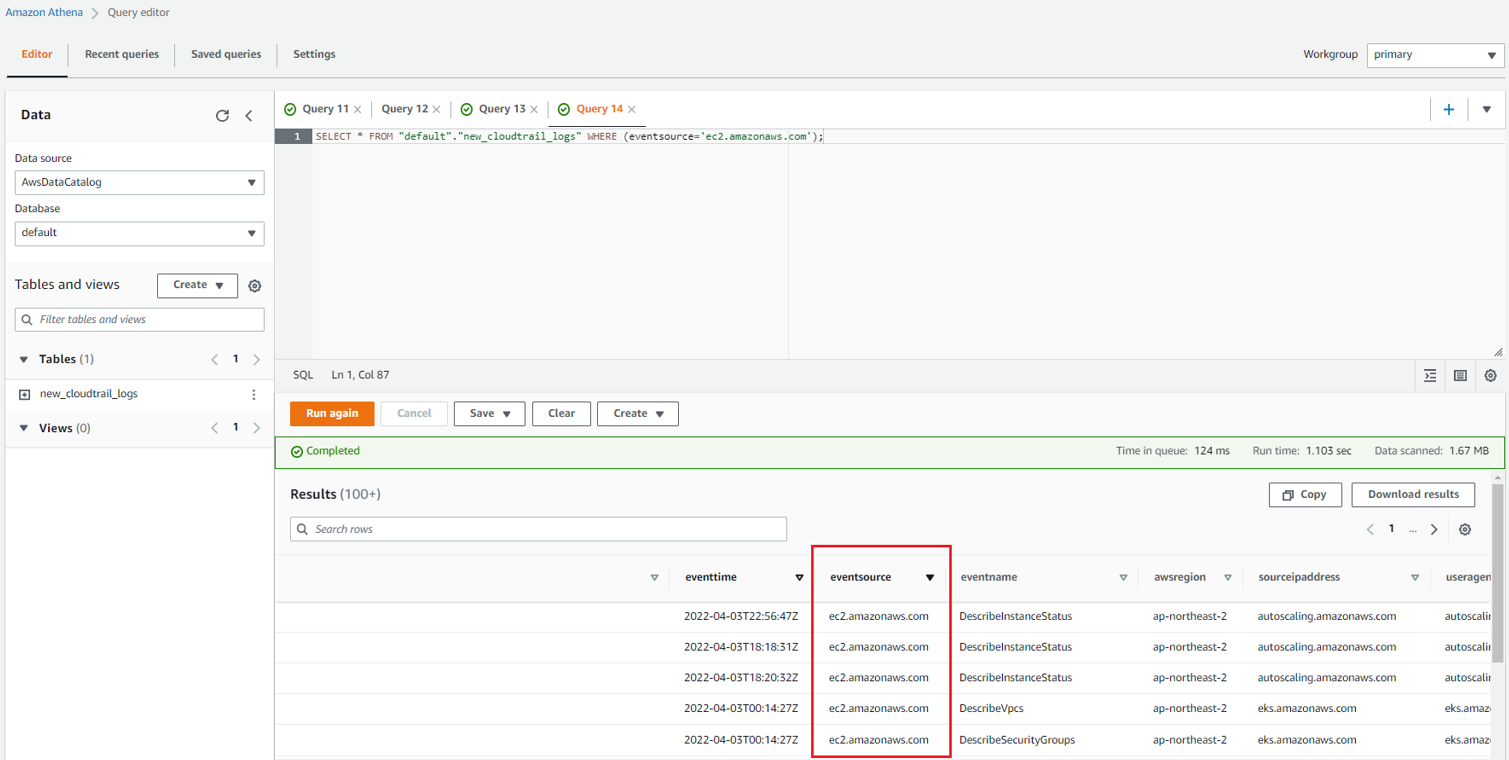
데이터가 잘 출력이 되고 있다. 해당 결과 문은 아까 지정한 S3버킷 경로에서 파일로 확인할 수 있다.
'STUDY > AWS' 카테고리의 다른 글
| [AWS] Amazon FSx for Windows File Server에서 Data Deduplication(데이터 중복 제거) 해보기 (0) | 2022.08.04 |
|---|---|
| [AWS] 모든 파일을 S3로 Copy하기 (--recursive, --exclude, --include 옵션 사용하기) (1) | 2022.08.01 |
| [AWS] EC2 Metadata 관련하여 (0) | 2022.06.28 |
| [AWS] Lambda를 이용해 Slack에 메세지 보내기 (0) | 2022.05.28 |
| [AWS] Lambda에 request 모듈 추가하기 (0) | 2022.05.28 |



