



| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Subnet
- RDS
- route table
- Storage
- storage gateway
- lambda
- Dedup
- 도메인
- dns
- Jenkins
- Python
- security group
- AD
- ncp
- VPC
- 윈도우
- Windows
- Linux
- Athena
- 네이버 클라우드 플랫폼
- ALB
- CloudFront
- FSX
- terraform
- 테라폼
- EC2
- CLI
- AWS
- S3
- NaCl
- Today
- Total
끄적이는 보송
[AWS] Amazon FSx에서 Data Deduplication(데이터 중복제거) 구현 및 주의사항 본문
디스크 사이즈는 나날이 커져가고 있으며 그만큼 더 많은 데이터를 저장할 수 있게 되었다. 하지만 결국엔 더 큰 디스크를 사용하더라도 같은 디스크에 잠재적으로 용량을 최대화할 수 있는 기회를 모색하는 것이 좋을 것이다. 그렇게 해서 나온 두 가지 방안이 "압축"과 "중복제거"이다.
AWS에서는 Amazon FSx for Windows File Server라는 서비스에서 이 "중복제거"라는 것을 이용할 수 있다. 참고로 "중복제거는 AWS의 기능이 아닌 Microsoft 사의 기능이다. AWS에서 Microsoft의 기능을 이용했다고 이해할 수 있는데, 그렇다고 M사의 중복제거 기능을 오롯이 전부 쓸 수 있는 것은 아니다. 자세한 건 밑에서 다루겠다.
중복 제거란
Data Deduplicaiton이 무엇인지는 아래 링크를 참고하자. 중복제거는 Microsoft 사의 기능으로 M사의 글을 참고하는 편이 더 많은 정보를 얻을 수 있다. 하지만 FSx의 중복제거와 M사의 중복제거에는 Default 설정값이라던지 입력하는 명령어 값에 약간의 차이가 있다는 점은 참고해두도록 하자.
https://learn.microsoft.com/en-us/windows-server/storage/data-deduplication/understand#how-does-dedup-work
Understanding Data Deduplication
Learn more about: Understanding Data Deduplication
learn.microsoft.com
결국 데이터 중복제거(Data Deduplication)를 이용하면 기존에 사용하던 Amazon FSx for Windows File Server Volume에 있는 Data 크기를 줄일 수 있다는 말이다. 데이터 중복제거(이하 중복제거)를 수행하기 위해서 FSx의 리소스를 소모하며, 다른 작업(대규모 파일 이동, Shadow Copies etc...)이 있는지, 만약 있다면 스케줄링을 조정하여 피해야 하는 등 고려 요소가 있다.
일반적으로 범용 파일 공유의 경우 평균 50–60%를 절약할 수 있다. 공유 내에서 사용자 문서의 경우 30~50%에서 소프트웨어 개발 데이터 세트의 경우 70~80%까지 절약할 수 있다. 실제로 필자의 경우, 약 55% 정도의 공간을 세이브할 수 있었다.
중복제거가 AWS의 기능이 아니라서 그런지 AWS Document의 설명이 굉장히 미흡하다. 설정에 대하여 보다 자세한 자료를 참고하고 싶다면 아래 링크를 읽어보는 것도 괜찮을 것 같다.
https://learn.microsoft.com/en-us/powershell/module/deduplication/?view=windowsserver2022-ps
Deduplication Module
Use this topic to help manage Windows and Windows Server technologies with Windows PowerShell.
learn.microsoft.com
중복제거는 어떻게 동작할까
중복제거는 Volume의 효율성을 위해 동작하는 대표적인 세 가지 작업이 있다.
- Optimization: 데이터를 Chunk 단위로 쪼개고 중복되는 Chunk를 고유하게 하여 Chunk Store에 저장하는 역할
- Garbage Collection: 최적화 작업 후 더 이상 참조하지 않는 불필요한 청크를 제거하여 디스크 공간을 회수하는 역할
- Scrubbing - 배드 섹터나 디스크 오류로 손상된 Chunk Store의 Chunk 데이터를 식별하며, 복원하며 자주 이용되는 Chunk 데이터는 별도의 백업을 수행
1. data deduplication algorigthm이 대상 Volume을 Optimization(최적화) 정책을 충족하는 파일을 선별
2. 선별된 파일을 Chunk 단위로 쪼갠다.
3. 중복되는 Chunk를 고유하게 선별한다.
4. 고유하게 식별한 Chunk를 Chunk Store라는 곳에 저장한다.
5. 데이터는 reparse point로 chunk storage에 있는 중복 제거된 데이터를 바라본다.
6. Garbage Collection 작업이 Optimization 작업에 의해 남겨진 Chunk를 정리하여 스토리지 확보한다.
7. Scrubbing 작업은 Volume Disk의 베드 섹터나, 깨진 파일 복구하는 역할을 한다.
8. Optimization, Garbage Collection, Scrubbing의 세 가지 작업이 스케줄링되어 Volume을 최적화한다.
* 여기서 Chunk란 Data Deduplication chunking algorithm에 의해 선별된 비슷하거나 중복되는 파일의 섹션을 의미한다.
* Chunk Store는 중복제거가 고유한 Chunk를 저장하는 데 사용하는 컨테이너 파일이다.
* reparse point란 Windows NTFS 파일 시스템의 리디렉션 기능을 의미한다.
중복제거를 구현해보자
중복제거를 실행하기 위해선 FSx의 PowerShell Endpoint 값을 참고하여 직접 CLI 명령어를 통해 실행시켜야 한다. 여느 다른 서비스처럼 AWS CLI 명령어나 콘솔에서 수행하는 것이 아니다. 우선 FSx의 PowerShell Endpoint 값을 불러올 수 있는 환경을 준비해야 한다.

중복제거 활성화
중복제거 기능을 이용하려면 먼저 활성화를 해줘야 한다. PowerShell 창에 아래 명령어를 수행해 활성화를 할 수 있다.
Invoke-Command -ComputerName amznfsxzzzzzzzz.corp.example.com -ConfigurationName FSxRemoteAdmin -ScriptBlock {Enable-FsxDedup }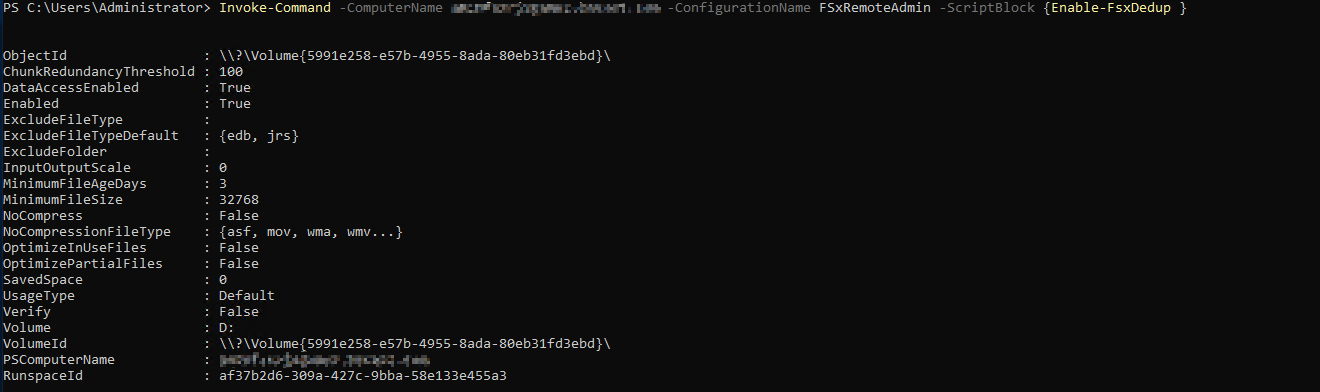
중복제거 활성화로 인해 생성된 Default Scheduled Task
중복제거를 활성화하면 위와 같은 Default 스케줄과 설정이 생성된다 (Optimization, Garbage Collection, Scrubbing). "BackgroundOptimization"을 제외한 다른 일정(Garbage Collection, Scrubbing)은 수정 혹은 제거도 가능하다.
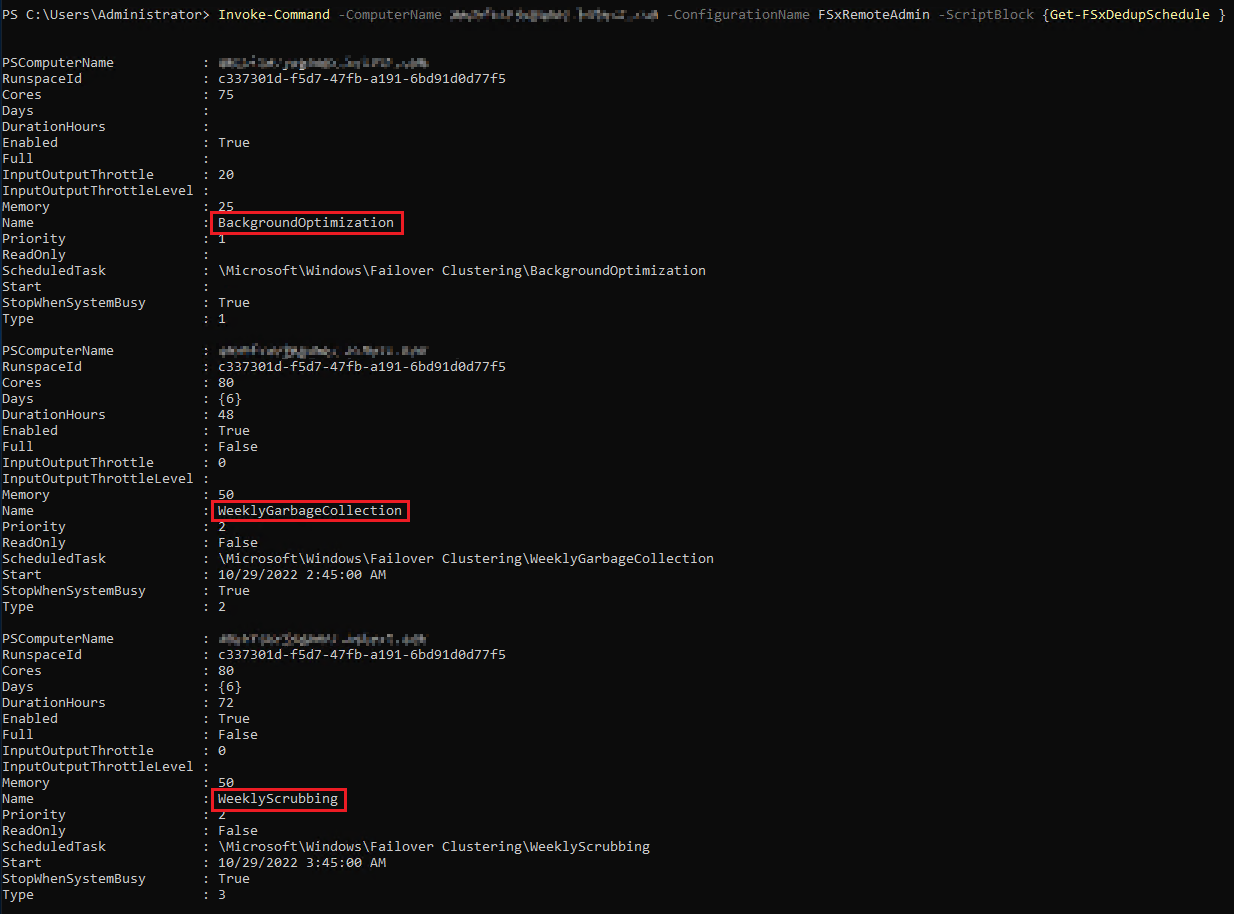
재밌는 점은 Default로 생성된 Task의 설정을 보면 Microsoft에서 공식적으로 안내하고 있는 설정값과 약간의 차이가 있다는 점이다. M사에선 35분에 작업 스케줄이 잡힌다는 것이 FSx Dedup에는 45분으로 설정되어 있었다. 왜 그런지 Global Support에 문의를 해봤지만 명확한 답변은 받지 못했다. 또한 명령어에도 약간의 차이가 있다. 예를 들면 M사는 그냥 dedup 명령어를 이용하지만 AWS의 경우 명령어에 FSx가 추가된다. 그냥 그렇게 생겨 먹은 거고 분명한 차이가 있다는 것은 염두하고 FSx Dedup을 이용하는 편이 좋아 보인다.

중복제거 Schedule 수정
아래 명령어 예제로 기존에 생성된 Scheduled Task의 설정을 변경할 수 있다. 명령어의 -Name 옵션 값에 기존의 Scheduled Task 이름값을 넣어 원하는 시간으로 수정하면 된다. 아래 예제는 매주 월, 수, 토요일 08:00에 Optimization(최적화) 작업을 수행하며, 최대 작업 시간은 7시간을 넘기지 않는다... 는 뜻이다.
Invoke-Command -ComputerName amznfsxzzzzzzzz.corp.example.com -ConfigurationName FSxRemoteAdmin -ScriptBlock {Set-FSxDedupSchedule -Name "CustomOptimization" -Type Optimization -Days Mon,Tues,Wed,Sat -Start 09:00 -DurationHours 9}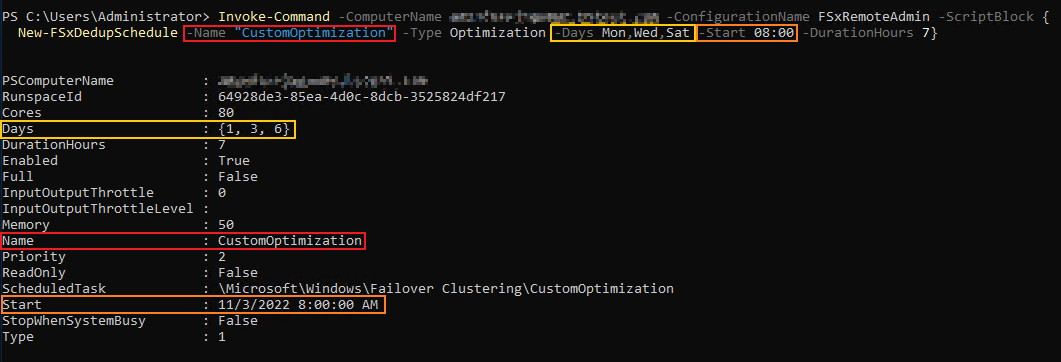
* Cores 옵션: 작업이 사용할 수 있는 시스템의 최대 CPU 사용률
* Memory 옵션: 작업이 사용할 수 있는 시스템의 최대 MEM 사용률
* Days 옵션: 작업 요일을 표현 (월(0) 화(1) 수(2) 목(3) 금(4) 토(5) 일(6) 규칙을 따름)
* Type 옵션: 해당 작업이 어떤 작업인지를 보여줌(1 = optimization, 2 = garbage collection, 3 = scrubbing)
* StopWhenSystemBusy: 시스템 부하 발생 시 작업 중지. 이후 다음 작업이 실행될 때 이어간다.
* DurationHours 옵션: 이 값은 작업 실행을 허용해야 하는 최대 시간을 의미한다. 작업이 DurationHours 값을 초과하게 되면 서버는 해당 작업이 유휴 시간이 아닌 시간에 작업이 실행되는 것을 방지하기 위한 작업을 멈추게 된다. 작업은 멈추더라도 기존에 중복 제거된 작업은 유지된다. 그리고 다음 작업이 시작할 때, 중복제거 작업을 이어받게 된다.
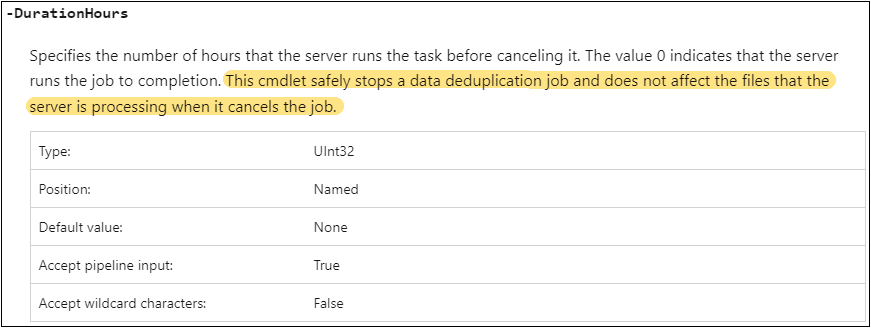
중복제거 Schedule 새로 생성
Task Schedule을 새로 생성하는 것도 큰 차이는 없다. 수정이 Set 명령어라면 생성은 New 일뿐이다.
Invoke-Command -ComputerName amznfsxzzzzzzzz.corp.example.com -ConfigurationName FSxRemoteAdmin -ScriptBlock {New-FSxDedupSchedule -Name "CustomOptimization" -Type Optimization -Days Mon,Tues,Wed,Thur,Fri,Sat,Sun -Start 09:00 -DurationHours 9}제대로 출력되지 않는 Task 설정 값 불러오기
또 다른 예제로 월~일 매일매일 09:00에 Optimization 작업을 수행하는 명령어이다. 하지만 'Days' 페러미터 값을 자세히 보면 상당히 모호하다는 것을 알 수 있다. 이것만 보아선 월 ~ 목요일까지 작업이 실행되는 것은 알 수 있지만 그 이후의 작업은 어떻게 되는지 알 수 없다.
나는 분명 Task Schedule을 월~일 매일매일 실행되도록 설정했다. 그렇다면 'Days' 페러미터 값은 {0, 1, 2, 3, 4, 5, 6}이 되어야 한다. 하지만 내가 돌려받은 값은 {0, 1, 2, 3...}이었다. Task Schedule를 다르게 설정해 보아도 'Days'를 일정 값 이상 넣게 되면 '. . .'으로 생략되어 버린다는 것이다. 이렇게 되면 어딘가 히스토리를 공유하지 않는다면 다른 작업자가 보았을 때, 이 Task Schedule이 언제 실행될지는 월~수 까지는 알아도 그 이후는 알 수가 없다.

여기서 팁이라면 팁일 수 있는 부분이 있다. 먼저 Task Scheduled을 $를 사용하여 shortcut을 생성하고 이 shortcut의 'Days' 값에 'Ft -AutoSize' 혹은 'Format-Table -AutoSize'를 이용하면 잘렸던 값을 출력해서 확인할 수 있다.
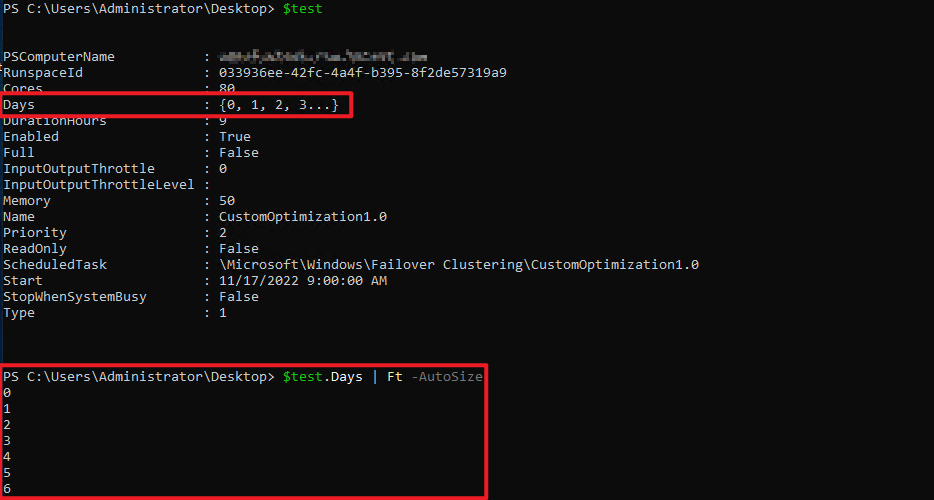
중복제거의 작업 내역/결과 출력하기
아래의 "Get-FSxDedupStatus" 명령어로 중복제거 작업 내역을 확인할 수 있다. 하지만 가장 최근 작업 내역만 확인할 수 있을 뿐, 그 이전에 발생했던 작업 내역(모든 히스토리)은 확인할 수 없다. 이 점은 유의하자
Invoke-Command -ComputerName amznfsxzzzzzzzz.corp.example.com -ConfigurationName FsxRemoteAdmin -ScriptBlock {Get-FSxDedupStatus}이외의 다른 중복제거 명령어
이외에도 아래의 명령어로 중복제거를 이용할 수 있다. 실제로 중복제거 명령어는 이것보다 더 많다. 하지만 안타깝게도 아래 AWS Document에 명시되어 있는 명령어 리스트가 Amazon FSx for Windows File Server에서 사용할 수 있는 명령어의 전부라고 한다.
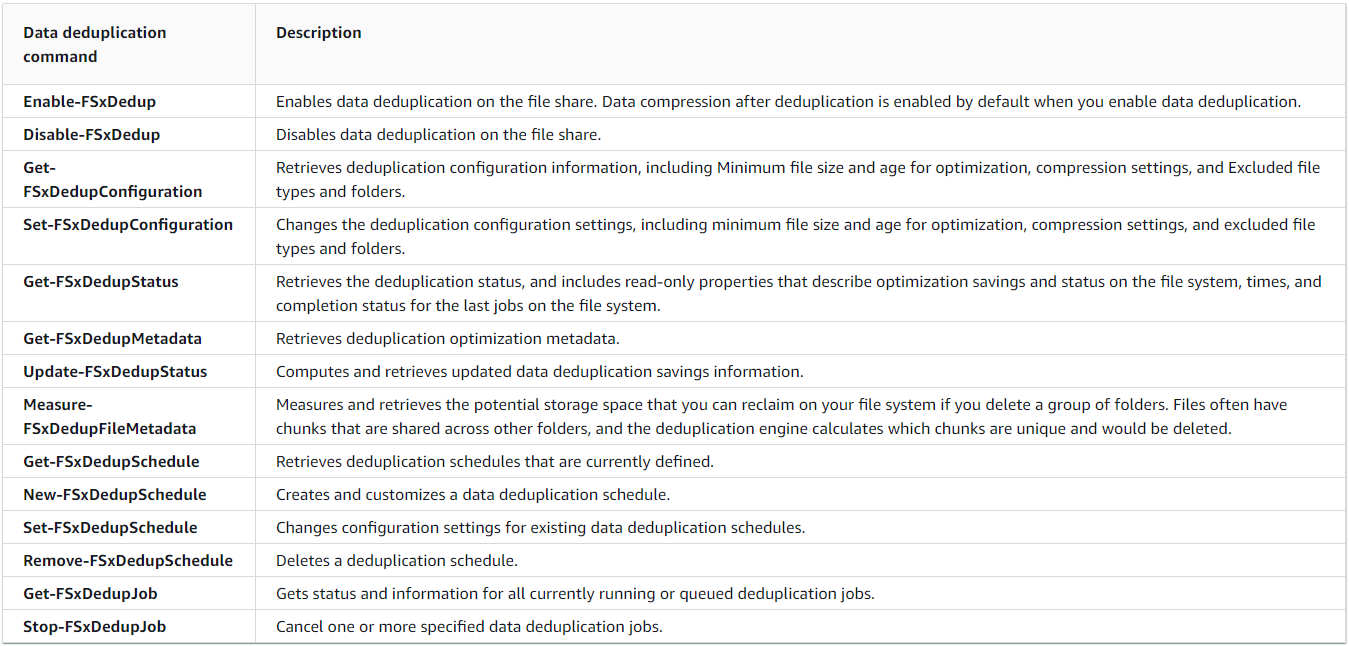
예를 들면, "Start-DedupJob" 명령어로 Manual 하게 중복제거를 실행할 수 있다. 하지만 Amazon FSx Dedup은 이 명령어를 지원하지 않아, 결국 중복제거 작업 스케줄을 생성하고 예약한 시간이 오기까지 기다리는 수밖에 없어진다. 하지만 결구 이것도 Windows 기반이니 여러 명령어를 시도해 볼 가치는 있다. 어쨌든 이 부분은 많이 아쉬운 점이라 개선이 되었으면 좋겠다.
중복 제거 이용 시, 참고 및 주의사항
1. 중복제거는 computing resource를 잡아먹는 작업이다.
즉, FSx의 스펙이 받쳐줘야 한다는 뜻이며, 스펙이 부족하면 사용자 이용에 불편을 야기할 수 있다. 참고로 Dedup Task 생성 시 'Core'나 'Memory' 등으로 성능을 제한할 수 있다. 하지만 이는 어디까지나 Task 하나 당 제한 설정일 뿐이며, 작업 시간이 겹치는 Task가 없는지 확인할 필요가 있다. (MAX CPU Utilization을 80% 설정을 한 Task 두 개가 동시에 돌아간다고 FSx의 CPU computing power를 두 Task가 80%를 알아서 나눠갔는다고 생각하면 안 된다.)
2. 중복 제거된 파일은 다시 해지될 수도 있다.
중복 제거된 파일을 수정하거나 이동하면 중복제거는 해지되어 원래 File Size로 돌아가게 된다.
3. 중복 제거된 파일을 다른 곳에 복사해도 원래 파일 사이즈로 복사된다.
예를 들어, 중복제거로 작아진 파일을 DataSync를 이용해 다른 FSx로 옮기려 한다고 가정해 본다. 하지만 복사하더라도 중복제거가 적용되지 않는 각 파일의 형식을 복사하기에 원래의 파일 사이즈가 이동되게 된다.
4. 중복제거된 FSx Volume을 스냅샷 생성하고, 이것을 기반으로 새로운 FSx를 생성하면 중복제거는 유지된 채 생성된다.
5. 도중에 중지된 중복제거 작업은 다음 작업에서 이어간다. 초기화되지 않는다.
5. 중복제거 활성화 시, 디폴트로 생성되는 'BackgroundOptimization' Task는 수정도 삭제도 불가능하다.
6.Amazon FSx for Windows File Server의 Storage Capacity가 증가되어도 중복제거는 유지된다.

아래 AWS Document의 Note 설명을 읽어보면 조금 헷갈릴 수 있다. 정리하자면 결국 FSx Storage Capacity가 증가되어도 기존에 중복 제거되었던 파일들은 여전히 유지된다는 말이다. 하지만 OptimizedFilesSavingsRate값은 0이 된다.
7. 중복제거 실행 히스토리의 경우, 적어도 FSx Dedup은 가장 최근 작업만 확인할 수 있다.
'Get-FSxDedupStatus' 명령어를 이용해 작업이 언제 이뤄졌고 결과는 어떤지 확인할 수 있다. 하지만 그 이전 작업 내용은 출력이 불가능하다. 이 부분은 심히 아쉽다.
Amazon FSx for Windows File Server(HDD Type) 중복제거 적용 시나리오
대량의 데이터를 FSx for Windows File Server에 마이그레이션 하고자 하는 곳도 분명 있을 것이다. 적어도 나의 경험으로는 대부분 비용이 부담되어 FSx의 Storage Type을 HDD을 선택하고 Storage 비용을 줄이기 위해 중복제거를 요구하는 곳이 있다. 하지만 중복제거는 컴퓨팅 리소스가 필요한 작업이기에 SSD 타입에서 실행할 것을 권장하고 있다.
요약하자면 마이그레이션 할 대량의 데이터를 중복 제거하여 사이즈를 줄이고 이것을 HDD에서 운영하고 싶다는 것이다. 많은 고민을 했는데 내가 내린 결론은 아래의 시나리오다. (더 좋은 방법이 있다면 공유해주세요)
1. 마이그레이션 할 데이터를 조사하고 중복제거 시, 세이브될 데이터를 예상한다. (ex. 1000GB -> 500GB 예상)
2. 예상한 데이터 사이즈의 Storage Capacity의 FSx를 SSD 타입으로 생성한다.
3. 데이터 마이그레이션을 시작한다.
4. 데이터 마이그레이션과 동시에 중복제거 작업을 공격적으로(?) 실행한다.
5. 만약 FSx의 Storage Capacity가 부족하다면 Storage Capacity 추가하고 다시 중복제거를 실행한다. (이때 Saving rate는 초기화되므로 필요한 정보라면 어딘가에 노트해두자) Storage Capacity는 최소 10% 혹은 그 이상으로만 늘릴 수 있다.
6. 성공적으로 데이터를 욱여넣어 마이그레이션이 되었다면 FSx SSD 타입을 스냅샷 뜬다.
7. 이 스냅샷으로 HDD 타입의 FSx를 생성한다. (중복제거된 파일을 유지된다.)
8. 향후 유지보수를 위해 HDD 타입의 FSx에서도 중복제거를 활성화해준다.
9. 기존의 SSD FSx를 제거한다.
추가) Amazon FSx for Windows File Server의 요금체계 주의사항
AWS에서 안내하고 있는 FSx의 비용체계를 보면 정말 오해하기 쉽게 만들었다. 개인적으로 공식 문서 내용을 바꿔야 하지 않을까라는 생각이 들을 정도이다. 아래 요금 체계를 보자. AWS에선 FSx의 Storage 비용을 마치 중복제거를 이용하면 사이즈가 줄어들으니 그만큼의 비용이 청구된다는 듯이 안내하고 있다. EFS와 같은 Storage 비용체계처럼 느낄 수 있지만 전혀 아니다. 오히려 EBS Storage 비용체계에 가깝다.
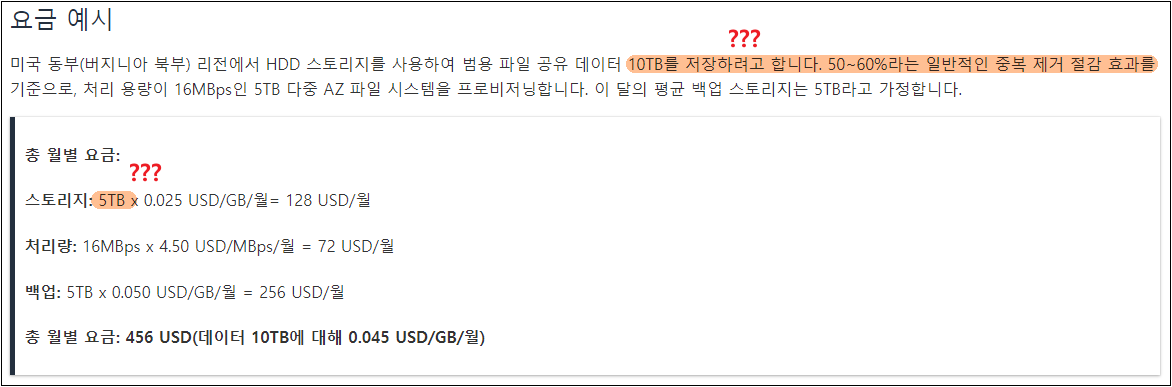
중복제거를 이용하면 데이터 사이즈가 줄어드는 것은 맞다. 하지만 Used Disk Space가 줄어든다는 것이지, 이것 때문에 비용이 줄어들지는 않는다. 한번 늘어난 FSx의 Volume은 다시 줄일 수 없다. 그리고 중복제거로 아무리 힘들게 데이터를 욱여넣어도 절대 저런 계산이 되지는 않느다. EBS 볼륨을 생각하면 이해가 쉬울 것이다. 잘 모르는 사람은 이것만 보고 싸다고 느낄 수 있고 나는 이걸 상술이라고까지 느끼고 있다. FSx 도입한다면 이 부분은 주의해야 할 것 같다.
약간의 착오가 있어 같은 내용의 포스팅이 하나 더 있다. 내용은 같지만 다른 부분도 있다.
[+] https://bosungtea9416.tistory.com/entry/FSx-%EC%A4%91%EB%B3%B5%EC%A0%9C%EA%B1%B0
[AWS] Amazon FSx for Windows File Server에서 Data Deduplication(데이터 중복 제거) 해보기
데이터 중복 제거란 (Data Deduplication) Amazon FSx for Windows File Server(이하 FSx)에 데이터 중복제거(Data Deduplication)이라는 기능이 제공된다. 데이터 중복제거란 혹은 줄여서 Dedup은(이하 중복제거) 데이터
bosungtea9416.tistory.com
'STUDY > AWS' 카테고리의 다른 글
| Amazon RI(Reserved Instance) 구입해보기 (0) | 2022.11.24 |
|---|---|
| lsblk -o +SERIAL 명령어를 이용한 EBS Volume Disk 찾기 (리눅스) (0) | 2022.11.22 |
| [AWS] Amazon FSx for Windows File Server Audit Log 활성화 및 객체 삭제 관련 감사 로그 (0) | 2022.10.24 |
| [AWS] Windows7에서 Storage Gateway 접근 안되는 문제 해결 (SMB protocol version 이슈) (0) | 2022.10.19 |
| [AWS] Amazon FSx Shadow Copy 구현 해보기 (0) | 2022.10.10 |



