



| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Jenkins
- RDS
- Athena
- lambda
- VPC
- Dedup
- ALB
- 네이버 클라우드 플랫폼
- 테라폼
- CloudFront
- Linux
- EC2
- Windows
- NaCl
- security group
- AD
- AWS
- storage gateway
- dns
- Python
- 도메인
- ncp
- route table
- CLI
- terraform
- S3
- Storage
- 윈도우
- FSX
- Subnet
- Today
- Total
끄적이는 보송
[AWS] CloudWatch에 지연되는 Aurora Metirc 분석해보기 본문
발단
같이 일하는 동료로부터 Amazon Aurora 분석 중, CloudWatch Metric 값에 이상한 점을 있다는 이야기를 들었다. 바로 Aurora의 몇몇 지표(volume iops 관련)는 CloudWatch 지표에 바로 반영되지 않고 느리게 쌓인다는 것이다. 적게는 10분 많게는 2~30분 정도, 혹은 그 이상으로 데이터가 현재 시간을 기준으로 지표가 느리게 출력되어 마치 바로 반영이 안 되는 모습을 보였다. 흥미가 생겨 분석한 내용을 포스팅해 본다.

혹시 Aurora의 다른 지표는 어떨까? 단순한 예로, CPUUtilization을 봤지만 디폴트 설정대로 정상적으로 5분 주기로 데이터가 찍히는 것을 볼 수 있었다. 확실히 volume IOPS 관련 지표는 다르다는 것이 보인다. 하지만 도큐먼트를 참고해 보면 VolumeIOPS 지표는 5분마다 쌓인다고 되어 있다. 랜덤 하게 쌓이는 내 환경과는 다르다. 아니면 도큐먼트의 내용을 내가 잘못 이해한 것일까?
원인
원인은 해당 볼륨 관련 매트릭은 일반적인 지표가 아닌 Billing 관련하여 참고하는 지표(VolumeReadIOPS, VolumeWriteIOPS, and VolumeByteUsed)라는 것에 있었다.
Billing 관련 지표는 주기적으로 기록되지 않으며, 일반적인 지표와는 다르게 동작한다. 내부 동작에 의해 조건이 충족되면 CloudWatch 지표에 기록되며, 그것이 20~30분 혹은 그 이상이 될 수 있으며, 빌링 계산은 1시간마다 이뤄지며 CloudWatch에는 5분 단위로 기록되는 것이었다. 이게 무슨 말이냐 하면...
예를 들어, 1:00~2:00시의 데이터를 내부 동작에 의해 조건이 충족되면, 2시 05분에 CloudWatch에 저장되며, 이때, 1:00, 1:05, 1:10... 2:00으로 저장된다는 의미이다. 그러므로 CloudWatch 상에서 실시간으로 확인하면 딜레이 된 것처럼 보였던 것이며, CloudWatch에 데이터가 기록된 시점은 해당 시간의 기록이 맞다는 의미다. 다만 실시간 기록이 아니기 때문에, 다른 지표와는 쌓이는 속도에 차이가 있는 것으로 보인다.
백번 양보해 이 지표들은 Billing 관련 지표이고, 그래서 다른 지표와 다르게 데이터가 쌓여 출력된다는 것까지는 이해했다. Billing 관련 지표는 이렇게 밖에 동작할 수 없는 이유를 찾아보려 벤더사에 문의도 해보았지만 내부 아키텍처라면 정확한 답변을 받지 못했다. 이 부분은 상당히 아쉬웠다.
Aurora 볼륨 관련 매트릭은 Billing을 위한 것?
Aurora에서의 빌링은 Storage rate 및 Volume에서의 데이터 변환, 즉 I/O Rate로 측정된다. 이때 참고하는 매트릭이 VolumeReadIOPS, VolumeWriteIOPS, and VolumeByteUsed 등이라는 것이다. 아래의 링크를 통해서 Amazon Auora에서 빌링이 계산되는 방법을 확인할 수 있다.
[+] https://aws.amazon.com/ko/rds/aurora/pricing/
아래 도큐먼트 링크를 통해, 해당 지표들이 Billing의 목적으로 사용됨을 알 수 있다.
[+] https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Aurora.AuroraMySQL.Monitoring.Metrics.html
[+] https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Aurora.Monitoring.Metrics.RDSAvailability.html
해결책은 없는가?
뭐 대충 해당 지표가 billing 관련이고 이렇게 밖에 제공되지 않는다는 것은 알겠다. 하지만 로드에 민감한 사용자라면 Aurora의 이런 특징이 크리티컬 한 문제가 될 수 있다. 당장의 과부하가 발생하는데, CloudWatch 지표는 이를 늦게 반영했을 경우, 알람이 뒤늦게 울리는 등 대처에 문제가 생길 수도 있겠다는 생각마저 든다.
결론부터 말하자면 추가 비용은 발생하겠지만 Aurora에 'Enhanced monitoring' 기능을 활성화해 주면 된다(니즈에 맞게 수집 간격을 지정해 주자). 이 기능을 활성화하면, Cloudwatch - Log groups에 RDSOSMetrics 그룹이 생성이 되는데, 이 값을 참고하면 된다.

Log groups 내에 기록된 Auroa log event 내용 중 일부(diskIO)
보면 알겠지만 그래프로 이쁘게 출력된 자료는 아니다. Log insight 기능을 통해서 데이터를 더 자세히 확인할 수 있는데, CloudWatch console에서 Logs -> Insight -> Log group에서 “RDSOSMetrics” 선택하고 아래의 쿼리를 입력 후, "Run query"를 클릭하여 원하는 데이터를 쿼리 할 수 있다. 만약 데이터가 쿼리 되지 않는다면, 필터에 의해 데이터가 제한된 걸 수도 있으니 각자 환경에 맞춰 커스텀해주자.
fields @timestamp, @message
| filter instanceID = "your_instance_id"
| parse @message /"timestamp":"\d+-\d+-\d+T(?<hour>\d+):/
| filter hour = 0 or hour >= 10
| parse @message /"diskIO":\[\{(?<MYdiskIO>[^}]+)\},/
| parse MYdiskIO /"writeIOsPS":(?<writeIOsPS>\d+\.\d+)/
| parse MYdiskIO /"readIOsPS":(?<readIOsPS>\d+\.\d+)/
| parse MYdiskIO /"device":(?<device>"[a-zA-Z]\w+")/
| filter (readIOsPS + writeIOsPS) > 1000
| sort @timestamp asc
| display @timestamp, device, readIOsPS, writeIOsPS, readIOsPS + writeIOsPS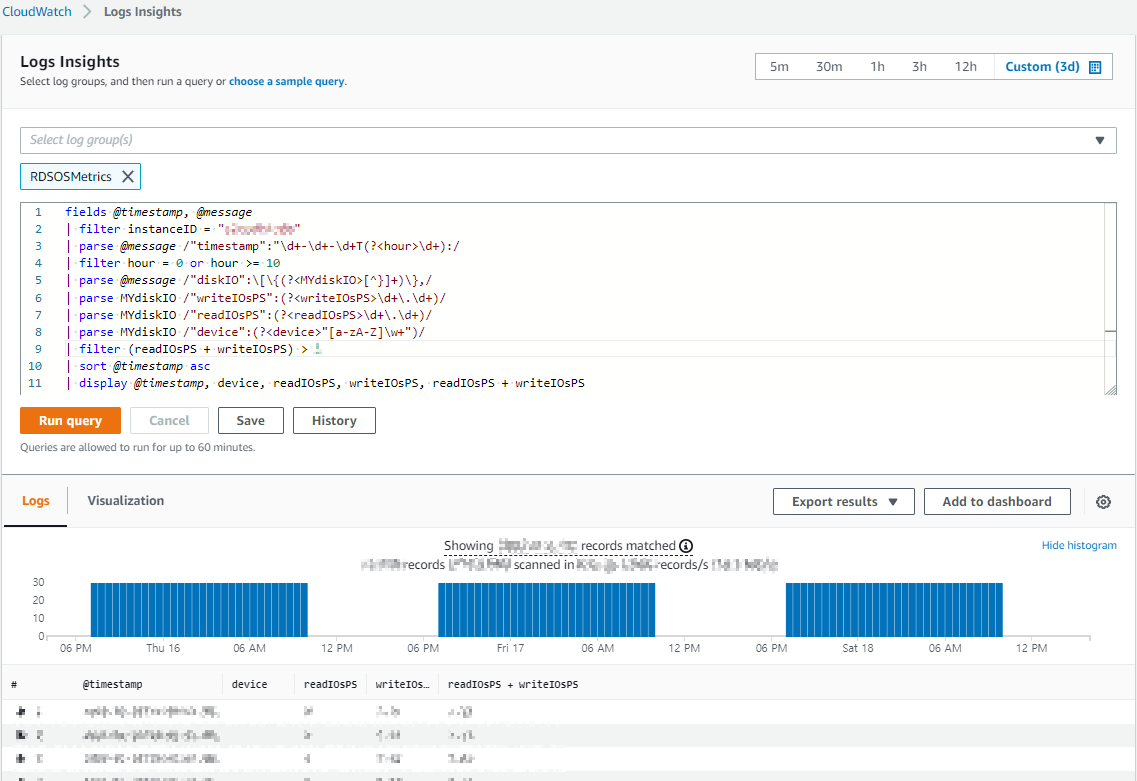
아니면 간단하게 RDS 콘솔화면의 Performance insight를 통해서 그래프로도 확인할 수 있다. 'RDS console -> DB 선택 -> Manage metrics -> OS metrics -> diskIO에서 readIOsPS/W riteIOsPS 등 선택'하여 확인할 수도 있다.
Log grups에 RDSOSMetrics 그룹의 데이터를 이용해 지표값에 대한 알람을 설정도 가능하다. 만약 Aurora volume iops 로드에 대한 즉각적인 알람이 필요하다면 하단의 링크를 참고할 수 있을 것 같다.
[+] https://aws.amazon.com/ko/premiumsupport/knowledge-center/custom-cloudwatch-metrics-rds/?nc1=h_ls
[+] https://github.com/awslabs/rds-support-tools/blob/main/cloudwatch/RDSCreateMetricsFromEnhancedMonitoring.py



