



| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- AWS
- Linux
- S3
- Python
- Jenkins
- AD
- lambda
- route table
- CLI
- Storage
- Athena
- VPC
- 테라폼
- EC2
- 네이버 클라우드 플랫폼
- RDS
- Windows
- FSX
- terraform
- Subnet
- ncp
- dns
- Dedup
- ALB
- security group
- storage gateway
- CloudFront
- NaCl
- 윈도우
- 도메인
- Today
- Total
끄적이는 보송
[AWS] Amazon ElastiCache 서비스 업데이트 관련 및 유의사항 본문
얼마 전 Amazon ElastiCache의 서비스 업데이트 알람이 뜬 적이 있었다. Amazon ElastiCache는 새로운 업데이트(최신 보안 패치, 버그 fix, 기능 향상 등...)가 출시되면 자동으로 업데이트 알리는데 나의 경우, 보안 업데이트와 엔진 업데이트였다.
Amazon ElastiCache 업데이트 시(혹은 수정) 걸리는 시간과 내부 동작 순서는?
전체 변경에 걸리는 시간은 각각 상이하겠지만 일반적으로 20분 내외로 진행되며, 리소스가 보유 중인 데이터의 양, 쿼리 사용량, 등에 따라서 전체 걸리는 시간은 더 길어질 수 있다.
실제 연결 끊김과 실패가 발생하는 시간은 1~2회의 수초 간의 시간이 발생할 수 있다. 하지만 Endpoint IP DNS 캐싱이 긴 경우 더 길어질 수 있다. Server update 적용을 위한 진행 시 AWS 내부의 진행 과정의 내용은 내부적으로 대략 아래와 같이 진행된다.
1. 내부적으로 "새 노드 클러스터" 그룹을 만듦
2. "기존 노드 클러스터" 그룹과 데이터를 동기화
3. "기존 노드 클러스터" 그룹 데이터 동기화 확인
4. "기존 노드 클러스터"를 "새 노드 클러스터"로 Failover 진행 ( 끊어지는 지점 )
5. "새 노드 클러스터"로 Endpoint DNS IP 업데이트 ( Client의 DNS cache 가 영향받는 지점 )
6. "기존 노드 클러스터"를 제거
7. Events 페이지에 완료 표시
위 과정은 사용자가 아닌 AWS에서 책임지고 수행하는 내부 과정이다. ElastiCache의 Endpoint의 경우에 서비스 가능 노드의 IP 만을 포함하도록 설계되어 있다. 당연하게도 사용 시간이 적은 때에 작업을 수행하는 것이 좋으며, 가능하다면 혹시 모를 상황에 대비해 백업을 해두는 것이 권장된다.
업데이트(혹은 수정) 방식
실제로 내부 시스템에서 리소스 변경이 일어날 때는 크게 두 가지 방식으로 접근된다고 한다. 각 방법은 내부의 작업절차에서 사용자의 리소스 상태를 확인하고 결정하게 된다. 실제로는 아래 두 방법 모두 1~2회의 수초 내의 연결에러 현상이 발생하게 되는 점에서는 동일하지만, 벌어지는 시간 기간의 범위가 달라지는 차이가 있다
1. 순차적인 변경
application이 시간 차를 두고 연결이 끊어졌다 접속하는 현상이 반복 (좀 더 넓은 시간 범위 동안 발생)
2. 준비후 동시 변경
application이 일시적으로 끊긴 후 동시에 접속 (좀 더 짧은 시간 범위 동안 발생)
업데이트 시(혹은 수정) 서비스에 미치는 영향은?
위에도 언급했다시피 새로운 노드가 생기고, 데이터 동기화를 마치면 노드를 '스위칭'하는 작업에 들어가는데 이때 순단 혹은 단절이 발생한다. 이를 잘 극복하기 위해서는 application의 Error retries and exponential backoff 방식의 Self Healing 형태의 재시도 방법이 필요할 수 있다.
[+] https://docs.aws.amazon.com/general/latest/gr/api-retries.html
Error retries and exponential backoff in AWS - AWS General Reference
Error retries and exponential backoff in AWS Numerous components on a network, such as DNS servers, switches, load balancers, and others can generate errors anywhere in the life of a given request. The usual technique for dealing with these error responses
docs.aws.amazon.com
또한 노드가 교체되었으니 IP도 달라졌을 테고 이 때문에 Endpoint 값이 수정되는데 기존의 Client 혹은 Application에 캐싱이 남아있다면 이 또한 문제가 될 수도 있다. 문제해결을 위해 application 수정이 필요할 수 있는데, 아래 DNS Cache TTL의 Java JVM을 예시로 기재되어 있는 링크를 참조할 수 있다.
[+] https://docs.aws.amazon.com/ko_kr/sdk-for-java/v1/developer-guide/java-dg-jvm-ttl.html
DNS 이름 조회를 위한 JVM TTL 설정 - AWS SDK for Java1.x
이 페이지에 작업이 필요하다는 점을 알려 주셔서 감사합니다. 실망시켜 드려 죄송합니다. 잠깐 시간을 내어 설명서를 향상시킬 수 있는 방법에 대해 말씀해 주십시오.
docs.aws.amazon.com
간혹 업데이트 작업 이후 변경된 Endpoint 값을 Application이 찾아가지 못한 이슈가 발생하고, 혹시나 캐싱 때문에 이전 IP주소를 바라보는 것은 아닌지 endpoint를 nslookup 하여 IP주소를 질의하는 경우가 생길 수 있다. 그렇게 질의해서 endpiont가 변경된 IP주소를 받는다고 해서 Application이 그 주소를 바라본다는 것을 의미하는 게 아니다. OS에 참고하고 있는 dns와 application 내 캐싱으로 남아있는 dns 정보는 다를 수 있다는 의미다. 잘못된 dns 값으로 application에서 ElastiCache 접속에 어려움이 있다면 에러로그를 참고해 보도록 해보자. 에러 로그에는 실제로 application이 endpoint 호출 시, 어떤 IP주소를 이용했는지 찍혀있을 수 있기 때문이다. 문제 해결이 안 된다면 애플리케이션 재기동이 답일 수도 있다.
결론부터 말하자면 노드가 한 개이건 두 개이건 순단은 발생한다. 순단은 모두 일어나고 Replica가 있는 경우, Master Failover 하기에 해당 재접속 시간이 짧아진다는 차이는 있다. 노드가 하나라면 순단이 아니라 단절에 가까운 현상이 일어난다.
만약 예약되어 있는 업데이트가 여러 개라면?
나의 경우, 업데이트가 두 개 잡혀있었다. 하나는 기한이 지나면 자동 업데이트되고, 하나는 안된다고 되어 있다. 일반적으로 업데이트는 따로따로 진행이 될 것이라 생각하겠지만 그렇지 않다. 둘 중 하나의 업데이트가 진행되면 나머지 업데이트도 전부 진행되어 버린다. 그리고 진행된 업데이트는 별도의 백업이 없으면 이전으로 롤백할 수 없다. 왜 그럴까?
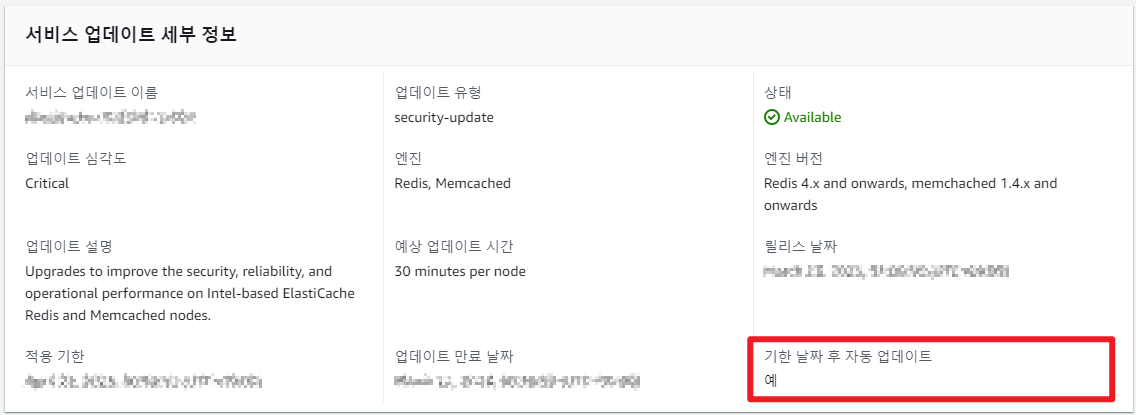

아까 위에서 언급했듯이 업데이트가 진행되면 "내부적으로 "새 노드 클러스터" 그룹을 만듦"다고 했었다. 이때 만들어진 노드는 이미 최신 패치가 다 완료된 노드이다. 그렇기 때문에 선택적으로 업데이트가 안 되는 것이고 굳이 그럴 이유도 없어 보인다. 여하튼 재밌는 부분이라 기재해 보았다.



